Since the deprecation of numeric data within SAINT classifications it has reduced the options for handling returns and margin data inside of Adobe Analytics. Arguably the Numeric Classifications created limitations that were challenging from an analysis perspective but either way I wanted to provide some options and recommendations on how to handle these two highly valuable data collection methods.
Returns Data
Option 1 = Data Upload
This would need to be done at the ‘Transaction ID’ level. This means that when an order is tracked on the website a Transaction ID would be generated by the Adobe libraries and then this would need to be stored in your back-end transactional systems. When you then upload a file of returns data you can bind the data using this same ID that then allows correlation back to the Visitor ID for which that Transaction ID also occurred.
When using this method it allows returns to be created at the individual product line-item level. For example, it is entirely possible that you might have an order with 3 products each of which have two units. The customer may only return 1 of each product (perhaps because they’re unsure of the exact fit of a garment?). In this instance you would want to upload 3 lines of data all with the same Transaction ID but different Product IDs and values of the returned item.
Pros:
- Can be batched/delayed in cases where you need to alter what you’re doing.
- Does not create any additional session data.
Cons:
- Transaction ID functionality needs to be enabled by Adobe and if the time period for using Transaction IDs is extended beyond 90 days a cost may be incurred.
- Requires an FTP bridge to be maintained between Customer and Adobe which is likely to require more maintenance over time.
Option 2 = Data Insertion
Instead of creating a batch job to upload a file to an FTP location you could create a bridge between your back-end and your live Report Suite in your Adobe Analytics account. In this case, when a transaction is tracked by Adobe you need to pass the Experience Cloud Visitor ID to your back-end systems.
When a return occurs (at the individual product level) you then need to fire a network request into Adobe using the API and using the ECID as the binding key. This does however act just like a regular server-call and therefore will look like a new session in the data-set.
Pros:
- Processed in real-time without having to handle timestamping.
- Once setup it should be easier to maintain.
Cons:
- Likely to be more effort to setup and test this initially due to risks
- If any errors/inaccuracies are present it is likely it might only be picked up after the data goes in. Once the data is in it can’t really come out.
- It will create an additional session for the users who have returns. This may be a desired activity but unlikely if that return can only occur offline.
My recommendation would most likely be to use Option 1 (Transaction ID method) as I believe the 90 day limit is unlikely to cause an issue with most return policies having expiration points within that time period. It will also be easier to setup and test before considering a more invasive data insertion option.
The results if this is done correctly can be dramatic. Rightly, if you calculate your returns data to be less than a few % points of total sales revenue maybe this does not justify the effort. However, in situations of seeing 5%+ returns (common across some verticals) we would highly recommend integrating with either of these options to get far more accurate behavioural and performance data. Imagine optimising media spend on a product that sells well but has such a high return rate that it equates to a negative media ROI… sure it looks great initially but the success of a company is more often than not tied to profitability, not revenue.
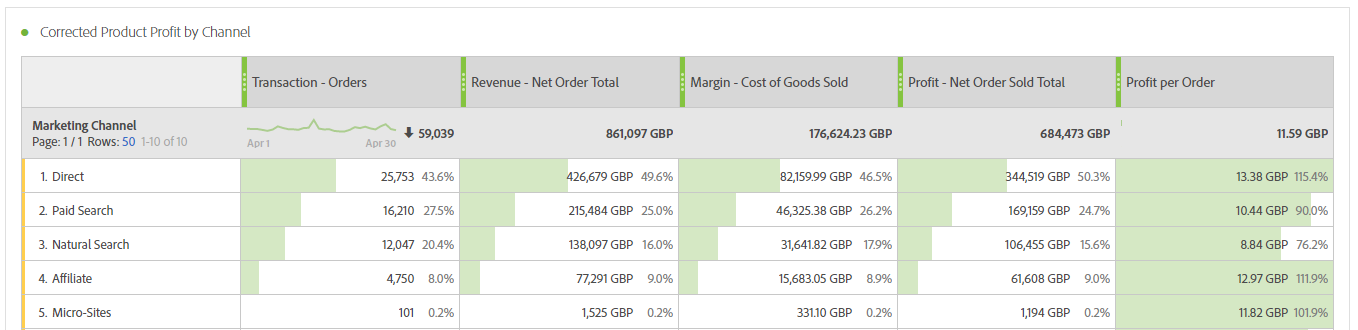
Here is an example of a very simple report illustrating how it could look in Workspace:
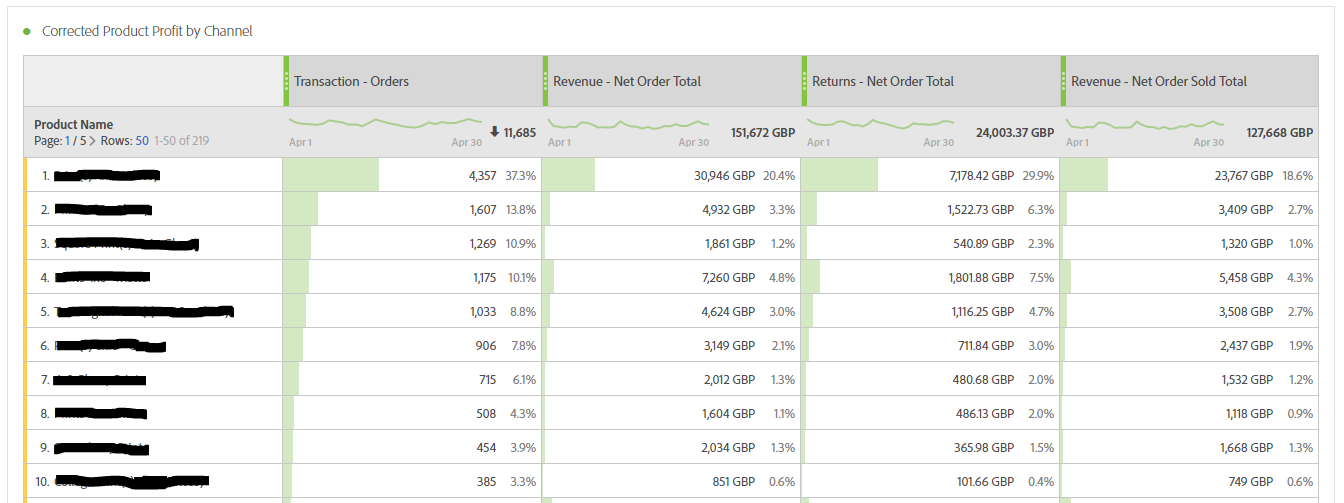
Margin Data
Option 1 = VISTA Rule
This requires an ‘Engineering Services Request’ to Adobe to manipulate your data at the point a hit is recorded. The way it would work is that you’d need to provide Adobe with a table of margin data at the Product ID level. The rules would be setup such that when an order occurred an additional margin event would be set at the product level to allow you to do all your calculations from a reporting perspective.
Pros:
- Does not risk any margin exposure to the customer.
- Relatively easy to create and update an excel file with margin data.
Cons:
- Can we expensive to create the ESR and then if your product range changes regularly it is a continued cost.
- No audit trail of what is going on. The only way of knowing if a VISTA rule is working and what it does is to get Adobe to document this and then you store/maintain is locally.
Option 2 = Data Layer
Same concept as above but you’d actually expose this data in the data layer. I imagine you’d want to avoid exposing the true value of the COGS in which case you’d probably want to expose a number that was a fraction of the true number and then use Calculated Metrics to normalise the figure. For example, if the margin on a £100 dress was £50 then you might want to push a data layer variable called ‘pm-calc=1.15’. No one would think this is a margin rate but in Adobe Analytics you would know that you need to divide the figure by 0.023 (one time setup in Calculated Metrics) to bring it up to your actual margin.
Pros:
- Once setup it will require very little maintenance or cost.
- All data available in real-time.
- All correlations you’d want would be possible.
- Any changes to margins over time are already accounted for automatically (in theory).
Cons:
- A bit risky in case customers/competitors somehow figure this out
- If someone makes a mistake and that mistake (or mistakes) is at the product level then all the data would be junk. If it’s just with the single division in the Calculated Metric this is ok but if the figure passed through is wrong for several products only then it would be a bit of a mess.
Option 3 = Data Upload
Exactly the same logic as the returns data. Instead of pushing an event with the value of the product being returned you would push in data with the margin of the product at the point the transaction occurred.
Pros:
- Provides broadly the same level of insight capability as the other options.
- Any changes to margins over time are already accounted for automatically (in theory).
- Gives some additional flexibility to stop an upload occurring if you spot an issue.
Cons:
- Requires margin to be defined for every product for every transaction which seems inefficient (unless already built into your systems).
- More points of failure when dealing with file uploads and FTPs.
My recommendation for margin data would generally be to consider Option 2 (Data Layer method) first. I would review this with your engineering team to decide how robust this method might actually be and if they have confidence in it before testing it. Not only will it provide the greatest reporting flexibility but it will also give you an additional data point to use for on-site personalisation – imagine if you could train your product recommendation algorithms to factor in higher margin items and what that might do to profitability.
If however there is question marks over the reliability of this method and/or the potential customer/competitor risk I mentioned then go for Option 3 first. Option 1 concerns me because the setup and maintenance cost are variables that will be far harder to control.
If done correctly the results can be dramatic. It will be possible to look backwards and provide reporting capability such as being able to return performance data for marketing channels against revenue vs margin. It will also, perhaps more powerfully, give you the ability to in real-time optimise towards product margin and not just products sold (or revenue achieved).