Problem
This isn’t actually a new problem. It’s the same issue that existed with Universal Analytics but got carried through to GA4. The issue sounds complicated but the result of it is actually painfully simple.
In GA4, when you report on ‘Active Users’ (also shown as ‘Users’) and ‘Sessions’, the number you actually get back in your reports within the interface may not be a true representation of what the actual distinct User count is and what would show up if you were extracting the data from BigQuery. The reason for this is that GA4 uses an approximate count distinct function using HyperLogLog++ to dramatically reduce processing time. The ‘full’ details of this can be found in this support article:
Now, there are actually two major issues with using ‘Users’ as a metric in GA4. The first issue relates to the use of the approximate count distinct function. The second is a more fundamental one related to how a ‘User’ is defined in the first place. Ultimately though, the resulting impact is that if your User metric is potentially incorrect you don’t stand a chance of being able to run a successful conversion rate optimisation or personalisation programme at scale. You could be in a situation where a large percentage of your results are being skewed in terms of their statistical significance meaning that you think an activity is performing well when it’s not or vice versa… I think it’s pretty clear why that is a problem!
Details
Let’s address HLL++ first. To avoid covering ground that other people have done I will refer you to a very good article that has already been written about this by Georgi Geogiev:
In summary, if you are trying to use GA4 to analyse the test performance of your CRO/Personalisation activities then you will almost certainly have inaccurate results if your activity samples contain more than 12,000 Users. The more Users you have the more inaccurate your results will be. 12,000 Users per activity, at least for the types of clients we work with, is something that normally gets achieved within a day or two from activities that will typically run for a minimum of 2 weeks.
Georgi goes on to give Adobe Analytics a bit of a roasting – I’m sure he has his reasons – but actually appears to misunderstand that Adobe Analytics isn’t trying to provide an accurate User count. It specifically does it using a Calculated Metric purely as an estimation and does not hide this fact. GA4 on the other hand could easily mislead people into believing the User count they see before them is correct when it in fact might be wildly inaccurate. He also misses the point that Adobe has another product on the market – I guess we can excuse this lack of knowledge as the article was first written in 2020 – Customer Journey Analytics. I will address this when I talk about the solutions for this problem.
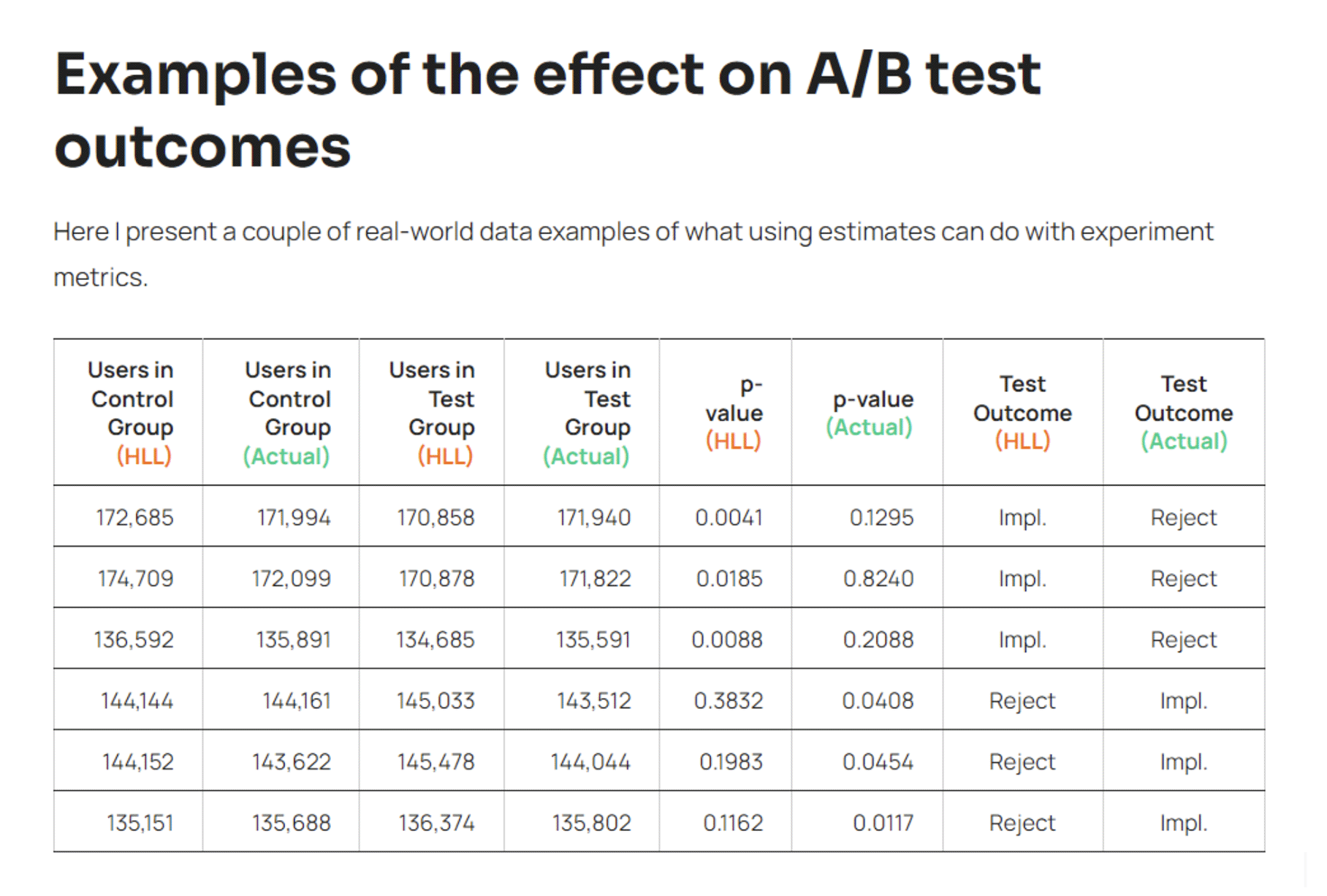
Source: Georgi Georgiev
Moving on to the second issue, how to define a ‘User’. I’ll try and keep this simple but you really need to appreciate what has happened in this industry with regards to GDPR, ITP and ATT to fully understand this. A ‘User’ is still just an approximation of an individual person. It is a blend of first party cookie IDs, device IDs and authentication data. If you want to watch a 30 minute video that explains these issues in a way that a normal human can understand and what their implications are then check out our first Fireside Chat about that.
In Google’s case the authentication data might be declared (when a customer provides details via a login action) or ‘modeled’ where a ‘modeled’ User is a result of a black-box computation from a combination of non-consented data points (yes, you read that correctly) and consented data points that Google doesn’t like very much (yes, you also read that correctly). Here’s an article where they try and explain what is going on without actually explaining it:
In short, GDPR, ITP and ATT are making Google’s life increasingly more awkward. In response to these regulations and privacy frameworks Google has actually – or at least seemingly for now – played a bit of a master stroke with their Consent Mode v2 updates. The net result of all of this is that they’re going to track data about everyone regardless of whether they consent or not and then play it back in the form of ad conversion data that people are expected to believe to define their ROAS. Why would anyone be sceptical about that!?
The point here is that regardless of whether the actual reporting interface is delivering back an accurate count of the data it seems there is a more fundamental issue with this in that the definition of a ‘User’ is to a certain extent what Google wants it to be in the first place.
Solution
The solutions proposed by others that have looked into this HLL++ issue with Google have often overlooked the more fundamental problem with the User count. Here at DMPG, because we have deep rooted experience and expertise in both the data collection and data activation industries we know that there are solutions beyond just trying to extract your data from BigQuery and build your own custom analytics visualisation system.
This is where one of the primary solutions we’re working with comes into frame – Customer Journey Analytics from Adobe. This is not a solution that you just turn on and it solves all of your problems… don’t be mad! It is however Adobe’s advanced analytics solution that sits inside of their Adobe Experience Platform. At the core of the solution is an identity resolution system that gives businesses the ability to stand the very best chance of being able to get to the most accurate determination of a ‘Person’ rather than just some approximation using cookies, device IDs, blackbox and wizardry.
Adopting a server-side SDK driven implementation that also uses an HTTP cookie and then enriching the Profile ID with declared IDs is going to give you the most accurate and normalised view of your User count and thus closest approximation (and in most cases it is always going to be an approximation) to a ‘People’ metric. Oh, and there’s no HLL++ nonsense in there whatsoever when pulling your People metric into any of the reports.
The reason why this tool is such a focus for us is that we are enablers of running CRO and Personalisation programmes at scale. We’re talking about programmes that, for a single client, operate across hundreds of millions of recipients, hundreds of thousands of products, thousands of activities per year and often across multiple brands, markets and languages. We need an analysis tool that allows us to be completely confident over the accuracy of the data we can record, can build unlimited complex segments to analyse different behaviours that define activity performance and gives our clients all of this at their fingertips without having to be SQL geniuses.
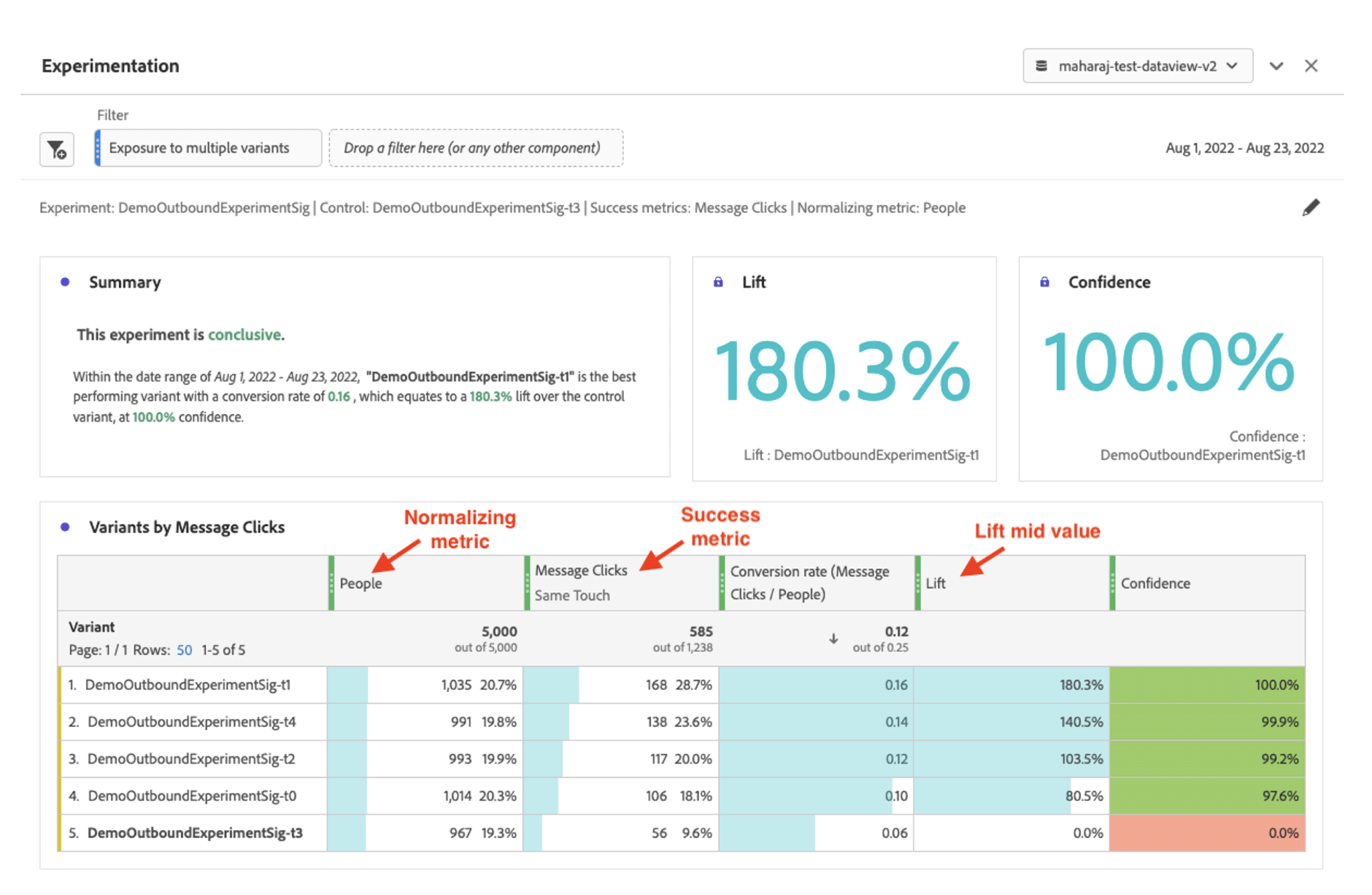
Source (with details about how confidence is calculated): View link to source
But, do we absolutely need CJA? If you’re trying to understand accurate performance of your CRO and Personalisation activities then technically no. The reporting interfaces within tools such as Optimizely, Adobe Target and Monetate will allow you to do this. You might even start to consider using tools like Mia Prova when building scale within your programme to help manage and report on all the data. However, if you are trying to build out a scalable programme that allows you to analyse performance against all of your other digital and non-digital data points in real-time… then yes, we would say you need it.
We’re in the process of writing up a detailed whitepaper to help businesses understand how they can capitalise on all the best parts of GA4 and CJA. In the meantime if you’d like to know more, then just get in touch. We love talking about this and would thoroughly enjoy helping to solve your challenges. The more complex the more fun they’ll be .